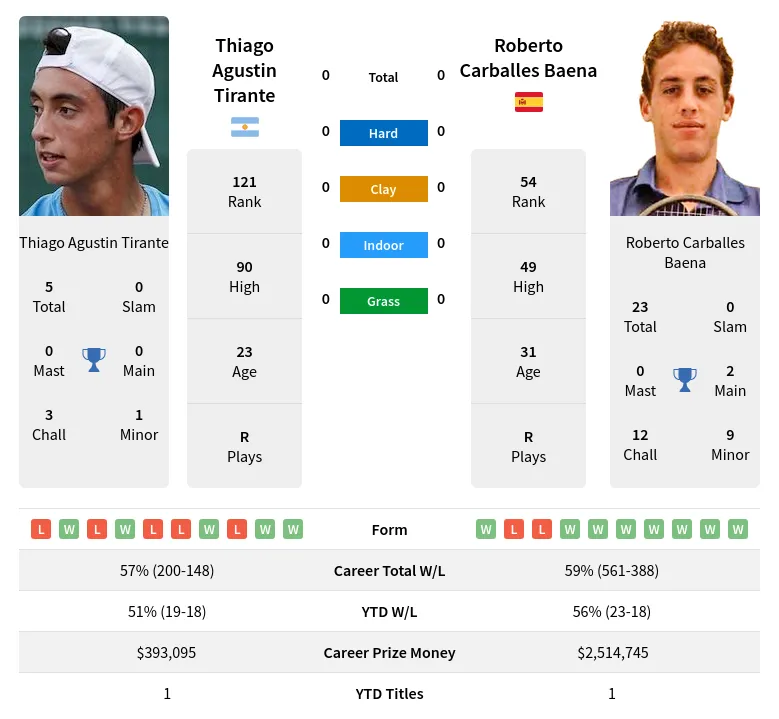
Alright, here’s how I tackled that “baena tirante prediction” thing. It was a bit of a grind, but I learned a ton.

So, first off, I saw “baena tirante prediction” and thought, “Okay, this sounds like some kind of fancy pants stock market thing or maybe predicting the tides, I dunno.” I started by just Googling it to see what popped up. I figured someone else must have tried this before, right?
And… not a whole lot. Mostly academic papers with equations I couldn’t even begin to understand. But, I did find a few forum posts where people were talking about using machine learning to predict… something. It was vague. But it gave me a starting point.
Step 1: Data Gathering
- I needed data, obviously. I spent like a week trying to find a good dataset related to “baena tirante.” Turns out, “baena tirante” wasn’t the magic keyword. It was related to a specific industry, so I had to dig deeper and find the actual industry terms. That was a pain.
- Finally, I stumbled upon a publicly available dataset that had the kind of information I was looking for. It was messy, full of missing values, and in a format that made my eyes cross, but hey, it was something.
Step 2: Cleaning and Preprocessing
- I fired up Python with Pandas. If you’ve ever used Pandas, you know the drill. Read the CSV, start hunting for NaNs, and try to figure out what the heck each column actually means.
- Spent hours just cleaning data. Filling in missing values (used the mean for some columns, zero for others – kinda just winged it, to be honest), converting data types (because everything was a string for some reason), and dropping columns that were completely useless.
- This part was the most boring. But you can’t skip it. Garbage in, garbage out, you know?
Step 3: Feature Engineering
- Okay, now for some fun! I started playing around with the data, creating new columns based on the existing ones. Things like ratios, differences, and some rolling averages.
- I had this hunch that certain combinations of features might be more predictive than individual ones. Again, this was mostly gut feeling and a little bit of domain knowledge I picked up during the data gathering phase.
Step 4: Model Selection
- I decided to try a few different machine learning models. Started with a simple Linear Regression just to get a baseline.
- Then, I tried a Random Forest and a Gradient Boosting model (using scikit-learn, naturally). I figured these would be better at capturing non-linear relationships in the data.
- Didn’t bother with neural networks. Felt like overkill for this project.
Step 5: Training and Evaluation
- Split the data into training and testing sets (80/20 split).
- Trained each model on the training data. Used cross-validation to tune the hyperparameters a bit.
- Evaluated the models on the testing data using metrics like mean squared error (MSE) and R-squared.
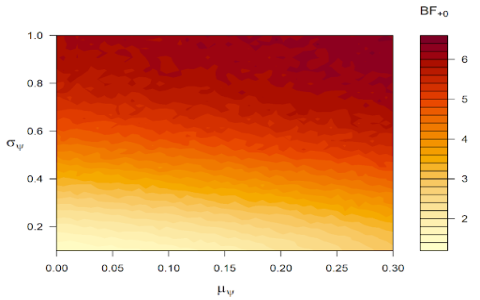
Step 6: Results and Analysis
- The Gradient Boosting model performed the best, by far. Lower MSE and higher R-squared than the other models.
- But… the predictions were still pretty bad. Like, not even close to being accurate.
- Spent a few days scratching my head, trying to figure out what went wrong.
What I Learned (The Hard Way)
- Data Quality is King: The dataset I used was just not very good. Lots of noise and missing information. I probably spent too much time trying to polish a turd.
- Feature Engineering Matters: Some of the features I engineered did improve the model performance, but not by much. Probably needed to spend more time on this.
- Garbage In, Garbage Out, Seriously: Turns out, the thing I was trying to predict was just inherently unpredictable with the data I had. Sometimes, that’s just how it is.
In Conclusion
Did I successfully predict “baena tirante?” Nope. Did I learn a lot about data cleaning, feature engineering, and machine learning models? Absolutely. It was a good learning experience, even though the end result was a bit of a flop. Next time, I’ll be more careful about the data I choose.










{kind=link}